Service Brokering: Introduction to a
Transformation-Based Approach
Stephen Potter, Marco Schorlemmer and Dave Robertson, CISA.
The brokering task
The Semantic Web ‘vision’ of is one of enhancing the representation of information on the web with the addition of well-defined and machine-processable semantics (Berners-Lee et al., 2001), thereby encouraging a greater degree of ‘intelligent’ automation in interactions with this complex and vast environment. One thread of this initiative concerns the provision of web-based services: the web has great potential as a medium for, on the one hand, web service-providers to advertise their services and conduct their business, and on the other, for those with particular service needs to publicise these to the environment so as to have them satisfied. However, currently lacking, and so preventing the full realisation of this service-oriented environment, is a means by which the available services are matched with the stated needs.[1]
Some sort of brokering mechanism is frequently suggested as playing this ‘middle agent’ role in distributed environments such as the web (Decker et al., 1997). Typically, this will involve the following sequence of actions: service-providers advertise their services to a broker using some pre-defined specification language (the location of the broker, it is assumed, being known to all agents involved) and the broker stores these specifications; service-requesters define their needs using the same specification language and post them to the broker; the broker attempts to match service with request to find one or perhaps more potential services; and finally, the broker responds to the requester by sending the details of the matched services, or else by directly invoking one of those services, receiving the results and passing these back, or else by indicating that no matching services have been found.
Within this general description, it can be seen that much depends on the adopted specification language: its form and content will determine, to a great extent, not only the sort of services that can be described but also, by extension, the scope of the broker, its application domain and the level of sophistication of the reasoning that it can apply during service matching. This language will have to be based on shared terms that have similar meaning to both provider and requester. Since different service ‘sectors’ will have their own distinctive languages and reasoning requirements, it does not seem reasonable to expect that a single broker will be able to cater for the environment as a whole; moreover, when one considers the overheads of maintaining, searching over and reasoning with the potentially very great numbers of service advertisements, nor does having a single broker seem desirable.
However, it is desirable that a broker should be capable of dealing with a reasonably wide range of services and requests, since otherwise this would entail a large number of brokers of limited scope, and the original service location problem merely shifts to become one of locating an appropriate broker. Balancing these contradictory impulses a priori would seem to be difficult; instead it seems likely that the more appropriate brokers will flourish as the environment evolves. What is needed, then, is some suitably flexible notion of – along with flexible mechanisms for – the brokering of service requests.
We propose a general flexible brokering mechanism based on the notion of web services as information transforming services. The particular transformation that a service performs is specified against a particular ontology; a service might be advertised to the broker through a number of different specifications, each against a different ontology. The theoretical scope of this broker will be constrained by the nature of the ontologies that it is able to process, and, more practically, by the actual ontologies of this nature that are available for service description in the environment. The adoption of this view of services allows reasoning that goes beyond simple matching: the broker is able to compose services into a sequence whose cumulative effect is such as to satisfy the request.
A service-oriented environment
The sort of distributed environment that we assume, then, contains a number of agents, each given a unique identifier (which is also used here for locating the agent – and which might be, for example, a URI); we distinguish between three different roles that an agent might play (and any given agent could conceivably play two or even all three roles, perhaps concurrently):
- agents which provide services and wish to make these services available to the agent community (service-providers). A particular service is identified by the combination of the name of the service and the identifier of the agent which provides it;
- agents that have tasks to perform but lack the means to perform them, and so look to the environment for services that will provide solutions (service-requesters);
- one or more brokers whose identifiers are known to other agents in the environment and which attempt to match service requests to appropriate available services: the response to a particular request is a message containing either one or more sequences of services or else some indication that no matching services could be found. A sequence of services consists of one or more services which would appear to meet the request when invoked in the stated order, with the service-requester providing the input to the first and receiving the output from the last, and the output of a service providing input to the next, if any, in the sequence. (Note that, according to this description, the broker does not invoke the services directly.)
Every agent also has some basic mechanism for communicating with other agents in the environment and some ACL layered on this for structuring inter-agent communications and indicating the type of a message; since these are not relevant to the current discussion, beyond assuming the existence of such mechanisms (and that these are robust and error-free), this paper will remain silent about such matters.
A service is here considered to effect some information transformation, that is, it is considered to take some information as input, manipulate this in some manner, and provide appropriate information as output of this process. Hence the description of an information transformation will consist of three principle elements: a description of the input, a description of the output, and a description of the transformation by which input is converted into output. This notion of an information transformation is intended to be general enough to cover a wide range of services in a wide range of domains; in practice actual services are described using task- or domain-dependent broker ontologies in which this notion of an information transformation is embodied. This leads us to give further consideration to the relationship between the brokering task and ontologies.
Brokering and ontologies
One can envisage a brokering mechanism that attempts to be ‘ontology-independent’, inasmuch as it tries to broker requests without recourse to the ontologies against which both services and requests are expressed.[2] While this means that such a broker would have wide applicability, it must rely on simple pattern matching between service description and request as their principal form of reasoning, which in turn relies on both service and request being described using identical terms with similar intended meanings. (Even were the broker to be given access to the service ontologies and the ability to process these, without some additional knowledge it will be unable to determine what constitutes valid ontological reasoning for brokering in that context.)
At the other extreme, the broker might be ‘ontology-dependent’, in that its reasoning is prefigured to operate using one or more particular ontologies with which to describe services: all services and requests are expected to be expressed against these ontologies, and the reasoning of the broker exploits knowledge of the structure and content of the ontologies. While this sort of broker would be capable of more powerful matching of service and request and might be well suited to the demands of particular service domains and environments, it would have to be re-engineered to address different domains. Moreover, the nature of these assumed ontologies becomes crucial: only if they are well-engineered and reflect the services in the domain accurately (and usefully) will be broker prove capable of meeting the needs of its environment. The presence of such characteristics in an ontology is difficult to assess a priori, and, while the use of long-established and accepted ontologies might inspire a certain degree of confidence, changes in the domain as it evolves may yet render these useless: flexibility has been sacrificed to the demands for greater reasoning power.
With this work, we propose a brokering mechanism that lies somewhere between these two extremes: the broker is prefigured to operate with particular types of ontology, and while it insists on the existence of certain high-level concepts in the ontology (a key notion in this work), cannot be considered dependent on a particular ontology.
In this environment, then, the existence of one or more ontologies (each also given a unique identifier) that describe information transformations is assumed. A particular broker will be able to process certain service ontologies; these can be identified either explicitly by their identifiers or else, in the more general case, implicitly by describing the sort of ontology ‘language’ that can be handled (this might be at the level of stating, for instance, that the ontology must be expressed in OWL, where this is appropriate, or else by providing a fuller account of the syntax and semantics of the ontology language if these do not conform to some accepted web standard – see the following section for an example of this). The content of such an ontology depends almost entirely on the domain in question with a single exception: the ontology must contain a definition of how an information transformation is described in this domain. In other words, if we define an information-transformation to comprise descriptions of input-information, output-informationandtransformation, these italicised terms must appear in the ontology as equivalences to domain concepts (hence, these terms are considered to be ‘reserved’ in the environment, and should not appear in ontologies with any meaning other than this). The effect of this is twofold: first, it provides the broker with a semantic ‘hook’ into the ontology, in order to understand the domain-specific transformations in terms of its existing generic notion of information-transformation; and secondly, it gives providers and requesters alike some explicit indication of the expected form and content of adverts or requests in the application area. (Again, the example in the following section should help clarify this use of the ontology.) Apart from the presence of this ‘hook’, then, these ‘broker ontologies’ can be considered conventional ontologies in every respect.[3]
Note that, in the description given above, a broker in this environment does not guarantee that any of the returned ‘solution’ sequences will meet the needs stated in the service request. This is, in part, a function of the ontology in question: ontologies may be abstract to a greater or lesser degree. While those that are more abstract will have a wider applicability and may be more appropriate for formulating and responding to imprecise service requests, their use will also be more likely to result in imprecise service sequences. Again, the usefulness or otherwise of particular ontologies is something that might be expected to emerge as the environment evolves, with the popularity of some confirming their worth while others fall into disuse. Furthermore, since a broker will be restricted to a particular ontology language(s), this will play a role in the nature of its response; more expressive ontology languages will allow more precise or detailed service descriptions and queries, but the broker may not be able to guarantee that all possible solutions may be found, or solutions within a certain time. In contrast, less expressive languages might confer certain attractive reasoning properties by restricting the form or content of descriptions. (As will be seen, the basic reasoning required of a broker, as it is envisaged here, is the ability to prove the subsumption of one term by another.)
An example broker ontology
We now provide an example ontology to illustrate some of the ideas outlined above. This ontology will also be used to describe example services and the brokering mechanism in later sections of the paper. First, however, it is necessary to give some account of the ontology language which our example broker comprehends; we do this explicitly by introducing the understood terms, along with their semantic definitions (for the purposes of illustration this ontology language is intended to be realistic without being overly complicated or sophisticated):
- class(C) defines a class (concept), here considered to be a collection of individuals in the domain of discourse. A class is a unary relation, C(x), which is interpreted as meaning that individual x is an instance of class C.
- subclass-of(C,P): class C is a subclass of class P if and only if every instance of class C is also an instance of class P.
- relation(R) introduces a relation R which is to be interpreted as defining a set of tuples that represents a binary relationship among individuals in the domain of discourse. Hence R(x,y) is interpreted as meaning that individual x stands in relation R to individual y.
- subrelation-of(R,P): R is a subrelation of P if and only if every tuple of R is also a tuple of P.
- implies(A,B): material implication (i.e., “if A then B”).
- and(A,B,...): logical conjunction, can take any number of arguments.
- thing, a term indicating the most general class and relation, a term indicating the most general relation.
Using this language, then, we can define ontologies which contain simple taxonomies of classes and relations, and axioms over these entities. One such ontology, with identifier nlp‑ont, describing natural language processing services, is given – in abbreviated form – in Figure 1. For the most part this ontology is fairly conventional in the entities it introduces and the relationships it defines between them. However, note the last section of constructs (highlighted in the figure) which directly relate the key terms input-information, output-information, transformation and information-transformation to elements of the domain: it is this knowledge that the broker expects to find in the ontology and will exploit in its algorithm for service discovery in this domain.
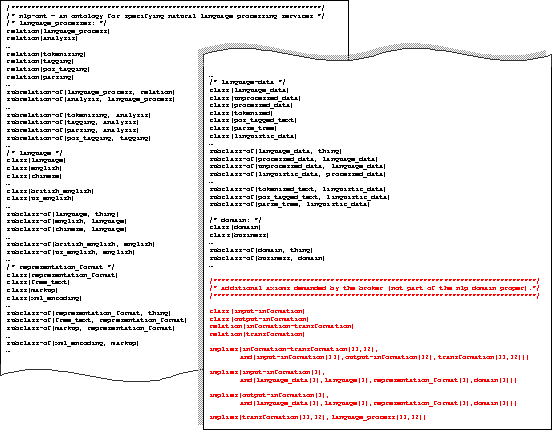
Figure 1. A fragment of a broker ontology, nlp-ont, for describing natural language processing services. (The construct /*…*/ is used here to denote a comment.)
Describing service capabilities
So, the axioms state that an
information-transformation relationship between x and y implies that x
is input-information, y is output information and there is some
transformation between them. (From a service-oriented perspective, this
might be read intuitively as stating the capability of the
service: it is capable of effecting a transformation of some
input x into output y.) The capabilities of actual
services in a particular domain are defined as refinements of this
formula; permitted refinements are defined by the additional ontology
axioms relating input‑information, output‑information,
and transformation to the ontology proper.
Hence, for this ontology, possible refinements are as shown graphically in Figure 2.
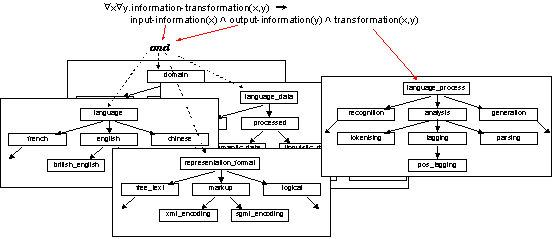
Figure 2. Refinement of information-transformation. (Red arrows denote implications, dashed black arrows conjunction of terms, and solid black arrows subterm relationships.)
Advertising services
So, given a formalism for describing the capabilities of services as declarative information-transformations, it is now possible to introduce a manner of describing services. A service can be described with the following tuple:
service = <provider-id, ontology-id, capability>
where:
- provider-id is the identifier of the service-providing agent in question (again, in the context of the WWW, this might be the URI of the service);[4]
- ontology-id is the identifier of a broker ontology;
- capability is a description of an information-transformation, expressed according to the named ontology, defining the input and output information and transformation of the former into the latter: this is a description of the capability of the service that the provider wishes to make available to agents in the environment.
Note that a given service might be described a number of times as providing different capabilities according to different ontologies: this is entirely consistent with our conception of brokering in this environment.
Service requests have an analogous form:
request = <requester-id, ontology-id, desired-capability>
with:
- requester-id is the identifier of the service-requesting agent;
- ontology-id is the identifier of a broker ontology;
- desired-capability is a description of an information-transformation, expressed according to the named ontology. Hence, the requester indicates the service it requires by providing the description of a service capability.
These two constructs, then, provide a description of the content of incoming messages to the broker: service tuples are used by service-providers to advertise their services and request tuples by service-requesters to specify their requirements.
Acknowledgements
This work is supported under the Advanced Knowledge Technologies (AKT) Interdisciplinary Research Collaboration (IRC), which is sponsored by the UK Engineering and Physical Sciences Research Council under grant number GR/N15764/01. The AKT IRC comprises the Universities of Aberdeen, Edinburgh, Sheffield, Southampton and The Open University.
References
Berners-Lee, T., Hendler, J. and Lassila O. (2001). The Semantic Web, Scientific American, May 2001.
The DAML Services Coalition (2003). DAML-S: Semantic Markup for Web Services, v0.9. See: http://www.daml.org/services/daml-s/0.9/daml-s.pdf
Decker, K., Sycara, K., and Williamson. M., (1997) Middle-Agents for the Internet. Proc. 15th IJCAI, pp. 578-583, Nagoya, Japan, August 1997.
Guarino, N. (1998). Formal Ontology and Information Systems, in N. Guarino (ed.), Formal Ontology in Information Systems, Proc. FOIS ’98, Trento, Italy, 6-8 June 1998. IOS Press, Amsterdam, pp. 3-15.
Li, L. and Horrocks, I. (2003). A software framework for matchmaking based on semantic web technology. In Proc. of the Twelfth International World Wide Web Conference (WWW 2003), pp. 331-339, 2003.
McGuinness, D.L. and van Harmelen, F. (Eds.) (2003). OWL Web Ontology Language Overview ‑ W3C Candidate Recommendation 18 August 2003. See: http://www.w3.org/TR/owl-features/
Mandell, D.J. and McIlraith S.A. (2003). A Bottom-Up Approach to Automating Web Service Discovery, Customization, and Semantic Translation. In Proc. 12th International World Wide Web Conference Workshop on E-Services and the Semantic Web (ESSW '03). Budapest, 2003.
Schorlemmer, M., Potter, S. and Robertson, D. (2002). Automated Support for Composition of Transformational Components in Knowledge Engineering. Technical Report EDI-INF-RR-0137, The University of Edinburgh, UK.
van Harmelen, F., Patel-Schneider, P.F., Horrocks, I. (Eds.) (2001). DAML+OIL (March 2001) version (revision 4.2): Reference description of the DAML+OIL ontology markup language. See: http://www.daml.org/2001/03/reference